4 Memoria Compartida Distribuida.

4.1 Configuraciones Memoria Compartida Distribuida
computación paralela:
Un computador paralelo es un conjunto de
procesadores capaces de cooperar
en la solución de un problema.
El problema se divide en partes. Cada parte se
compone de un conjunto de
instrucciones. Las instrucciones de cada parte se ejecutan simultáneamente en
diferentes CPUs.
Circuitos Basados en Bus, anillo o con conmutador.
Arquitecturas de MCD
Existen varias formas de implantar físicamente
memoria compartida distribuida, a continuación se describen cada una de
ellas.
Memoria basada en circuitos: Existe una única área de memoria y cada micro tiene
su propio bus de datos y direcciones (en caso de no tenerlo se vuelve un
esquema centralizado)
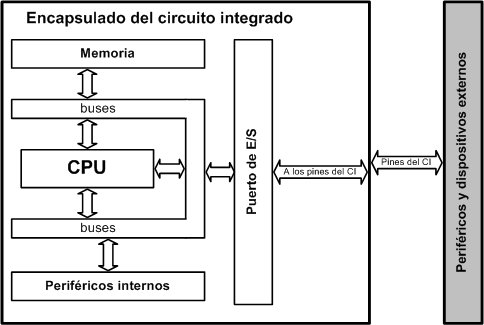
MCD basada en bus: En este esquema los micros comparten un bus de datos
y direcciones por lo que es más barato de implementar, se necesita tener una
memoria caché grande y sumamente rápida.

MCD basada en anillos: Es más tolerante a fallos, no hay coordinador
central y se privilegia el uso de la memoria más cercana

MCD basada en conmutador: Varios micros se conectan entre sí en forma de bus
formando un grupo, los grupos están interconectados entre sí a través de un
conmutador.
4.2 Modelos de Consistencia.
La duplicidad de los bloques compartidos aumenta el
rendimiento, pero produce un problema de consistencia entre las diferentes
copias de la página en caso de una escritura. Si con cada escritura es
necesario actualizar todas las copias, el envío de las páginas por la red
provoca que el tiempo de espera aumente demasiado, convirtiendo este método en
impracticable. Para solucionar este problema se proponen diferentes modelos de
consistencia, que establezcan.
Nombramos algunos modelos de consistencia, del más
fuerte al más débil: consistencia estricta, secuencial, causal, PRAM, del
procesador, débil, de liberación y de entrada.
Estricta Causal Secuencial Débil, de liberación y
de entrada.

Consistencia Estricta
El modelo de consistencia más restrictivo es
llamado consistencia estricta y es definido por la siguiente condición
Cualquier lectura sobre un item de dato x retorna un valor correspondiente con
la más reciente escritura sobre x
Consistencia Causal
es un debilitamiento de la consistencia secuencial.
Se hace una diferenciación entre eventos que están potencialmente relacionados
en forma causal y aquellos que no. Las operaciones que no están causalmente
relacionadas se dicen concurrentes.
La condición a cumplir para que unos datos sean
causalmente consistentes es:
Escrituras que están potencialmente relacionadas en
forma causal deben ser vistas por todos los procesos en el mismo orden.
Escrituras concurrentes pueden ser vistas en un orden diferente sobre
diferentes máquinas.
Consistencia Débil
Los accesos a variables de sincronización asociadas
con los datos almacenados son secuencialmente consistentes.
Propiedades
No se permite operación sobre una variable de
sincronización hasta que todas las escrituras previas de hayan completado.
Consistencia liberación (Reléase)
se basa en el supuesto de que los accesos a
variables compartidas se protegen en secciones críticas empleando primitivas de
sincronización, como por ejemplo locks.
4.3 Memoria Compartida Distribuida EN BASE A
PAGINAS
El esquema de MCD
propone un espacio de direcciones de memoria virtual que integre la memoria de
todas las computadoras del sistema, y su uso mediante paginación. Las páginas
quedan restringidas a estar necesariamente en un único ordenador. Cuando un programa
intenta acceder a una posición virtual de memoria, se comprueba si esa página
se encuentra de forma local. Si no se encuentra, se provoca un fallo de página,
y el sistema operativo solicita la página al resto de computadoras.
DISEÑO, REPLICA, GRANULARIDAD, CONSISTENCIA,
PROPIETARIO Y COPIAS.
El sistema
operativo, y en el caso del protocolo de consistencia de entrada, por acciones
de sincronización explícitas dentro del código del usuario. El hecho que la
especificación se encuentre dispersa dificulta tanto la incorporación de nuevos
protocolos de consistencia como la modificación de los ya existentes, debido a
que los componentes tienen además de su funcionalidad básica responsabilidades
que no les corresponden.
4.4 Memoria Compartida Distribuida EN BASE A
VARIABLES

La comparticion
falsa se produce cuando dos procesos se pelean el acceso a la misma pagina de
memoria, ya que contiene variables que requieren los dos, pero estas no son las
mismas. Esto pasa por un mal diseño del tamaño de las paginas y por la poca
relación existente entre variables de la misma pagina.
En los MCD basados
en variables se busca evitar la comparticion falsa ejecutando un programa en
cada CPU que se comunica con una central, la que le provee de variables
compartidas, administrando este cualquier tipo de variable, poniendo variables
grandes en varias paginas o en la misma pagina muchas variables del mismo tipo,
en este protocolo es muy importante declarar las variables comparitdas.
4.5 Memoria Compartida Distribuida EN BASE A
OBJETOS.
Una
alternativa al uso de páginas es tomar el objeto como base de la transferencia
de memoria. Aunque el control de la memoria resulta más complejo, el resultado
es al mismo tiempo modular y flexible, y la sincronización y el acceso se
pueden integrar limpiamente.
Otra de las
restricciones de este modelo es que todos los accesos a los objetos compartidos
han de realizarse mediante llamadas a los métodos de los objetos, con lo que no
se admiten programas no modulares y se consideran incompatibles.
4.6 Administradores de
memorias en clusters

Un cluster debe comportarse
como una sóla máquina Ambientes de gestión de recursos (PBS, SGE) y otro tipo
de enfoques como Mosix, cumplen con este propósito desde el punto de vista de utilización
Las herramientas de
instalación también facilitan la construcción del cluster. Sin embargo, la administración
aún se realiza nodo a nodo.

El administrador de un cluster debe tomar en cuenta algunos aspectos,
una vez que se ha completado la instalación de los recursos básicos de hardware
y software. Estos aspectos incluyen la configuración e instalación de un
sistema de archivos universal, la configuración y administración de recursos
mediante herramientas implementadas en software; el monitoreo de sus
actividades y el registro de cada uno de los eventos generados por la ejecución
de cálculos computacionales.
Varios de los sistemas más importantes para
la instalación automática de clusters, incluyen herramientas de monitoreo,
administración y registro de eventos mediante paquetes de distribución para
sistemas Windows y Linux. Entre estos sistemas están OSCAR y Rocks NPACI; ambos
sistemas permiten el uso de herramientas de software que tienen propósitos específicos
tales como:
• Definición y administración de nodos.
• Administración de colas por lotes (Batch Queue Management).
• Administración de recursos: grupos NIS
(Network Information Service), cuotas de disco y CPU.
• Administración de servicios de resolución
de nombres : DNS (Domain
Name System para clusters)..
• Registro de usuarios para clusters de dimensiones superiores a los 100
nodos.
• Monitoreo de carga.
La administración de clusters,
implica tomar medidas preventivas y planificar tareas. La administración
implica los siguientes aspectos:
• Registro de eventos.
• Monitoreo o medida del estado de los
recursos del cluster.
• Recuperación ante fallos de hardware,
software, incluyendo el sistema de archivos.
• Administración del registro de usuarios y
grupos de usuarios, de los servicios del cluster (accounting).
• Planificación de tareas y balanceo de
carga.
No hay comentarios:
Publicar un comentario